Abstract
The Instance Image Goal Navigation (IIN) problem requires mobile robots deployed in unknown environments to search for specific objects or people of interest using only a single reference goal image of the target. This problem can be especially challenging when: 1) the reference image is captured from an arbitrary viewpoint, and 2) the robot must operate with sparse-view scene reconstructions. In this paper, we address the IIN problem, by introducing SplatSearch, a novel architecture that leverages sparse-view 3D Gaussian Splatting (3DGS) reconstructions. SplatSearch renders multiple viewpoints around candidate objects using a sparse online 3DGS map, and uses a multi-view diffusion model to complete missing regions of the rendered images, enabling robust feature matching against the goal image. A novel frontier exploration policy is introduced which uses visual context from the synthesized viewpoints with semantic context from the goal image to evaluate frontier locations, allowing the robot to prioritize frontiers that are semantically and visually relevant to the goal image. Extensive experiments in photorealistic home and real-world environments validate the higher performance of SplatSearch against current state-of-the-art methods in terms of Success Rate and Success Path Length. An ablation study confirms the design choices of SplatSearch.
Experiment Video
SplatSearch Architecture
The proposed SplatSearch architecture consists of six main modules, Fig. 1: 1) Map Generation Module (MGM), 2) Semantic Object Identification Module (SOIM), 3) Novel Viewpoint Synthesis Module (NVSM), 4) View-Consistent Image Completion Network (VCICN), 5) Feature Extraction Module (FEM), and 6) Exploration Planner (EP). Inputs are RGB-D observations with corresponding poses from the robot’s onboard camera and a single goal image. These are first processed by the MGM, which incrementally constructs a sparse-view 3DGS map and a value map. The RGB-D observations and the 3DGS map are used as inputs into the SOIM, which analyzes the current RGB frame to detect candidate objects of the same class as the goal image. Detected objects are segmented, assigned unique identifiers, and their 3D centroids are mapped into the 3DGS representation, producing a set of candidate object locations. These centroids are used by the NVSM to render multiple candidate views of each detected object from novel poses around the centroid using the 3DGS map. Since these renders are often incomplete due to sparse reconstructions, they are refined by the VCICN by inpainting missing regions to produce complete views. The completed renders are compared against the goal image by the FEM using feature matching, outputting visual context scores that represent the likelihood of a detected instance matching the goal object. The EP uses the visual context scores and semantic scores obtained from a pre-trained image encoder to select frontiers for navigation. If a goal object is recognized, the EP plans a direct navigation path to its location; otherwise, it selects the next frontier that maximizes semantic and feature matching scores.
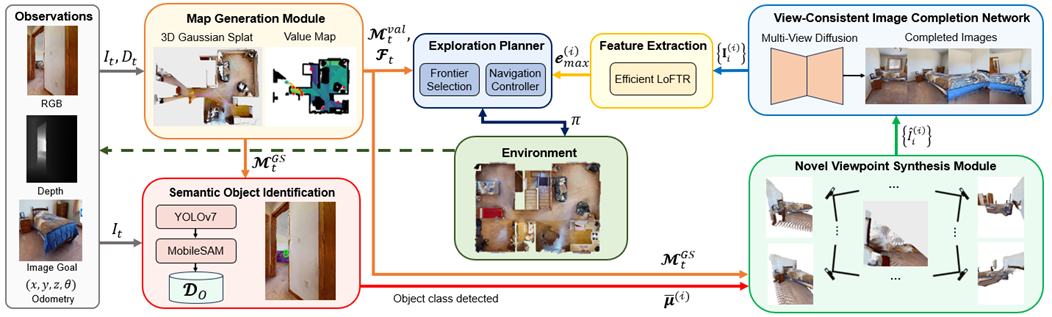
Fig 1. SplatSearch Architecture